Connected and Autonomous Vehicles
Collaborative Intelligence in Smart and Connected Vehicles
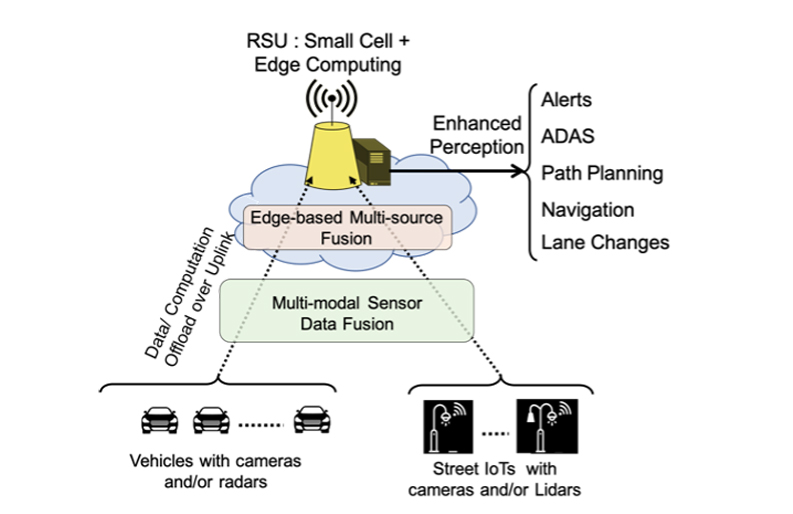
While Connected Vehicles can share their locations and plans with one another, it is challenging to ask other road users such as pedestrians or cyclists to do the same. Moreover, not all vehicles will be capable of this collaboration as some vehicles, especially older ones, will not have sufficient technology. We are examining ways for Connected Vehicles, along with the deployed infrastructure, to collaboratively perceive the environment in order to create exceptionally accurate and thorough roadway awareness.
This awareness will allow for better path planning to be undertaken by Autonomous Vehicles, humans through the usage of alerts and HUDs,and infrastructure through traffic and pedestrian management. In order to create this awareness we are developing techniques to fuse sensor data from multiple modalities, such as camera, radar, and lidar, on the same vehicle as well as multiple sources geographically separated throughout the environment, such as fusing the data between a vehicle and a street IoT camera.
View Sharing Between Vehicles Through 3D Feature Matching
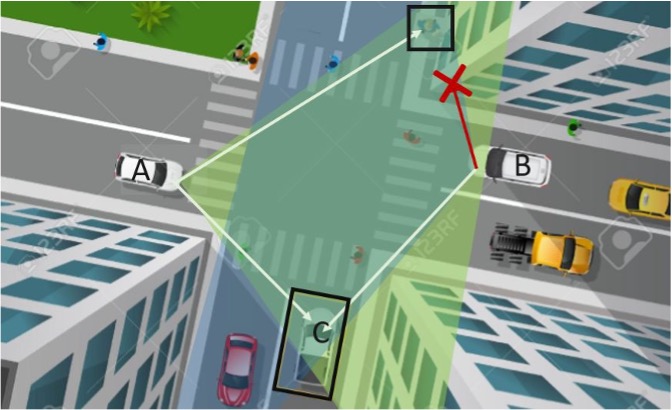
Occlusions and detection flaws may cause serious traffic accidents due to masking the presence of potential roadway hazards. Sharing views among vehicles is a key advantage of collaborative intelligence as it can greatly reduce these issues and thereby enhance roadway safety. In order to leverage multiple views, we first need to merge the information from the source vehicle coordinate system to the target vehicle (or centralized node) coordinate system. Fast and accurate 3D feature matching, together with GPS/IMU data and a statically collected point cloud of the area around the vehicles, can provide an accurate framework for merging multiple views. By finding correspondences between the point cloud generated by the vehicle’s sensors, and the static point cloud of the area, we can estimate the relative rigid transformation of the vehicle’s sensors and project the observed point clouds of multiple views into the same coordinate system.
The current state-of-the-art algorithms for finding correspondences between two point clouds include two steps: voxelization and feature extraction. A carefully handcrafted technique is picked to convert the local point cloud around each key point into a voxel grid. This voxelization step not only addresses the order-less issue present in point clouds but allows the following feature extraction network to take the advantage of the spatial information as well. The feature extraction network generates dense feature vectors of each input keypoint that can be used for comparison across multiple views. We are developing techniques to replace the currently handcrafted voxelization step with a compact neural network. This replacement will remove the bottleneck in processing speed and improve the algorithm’s robustness against noise and variations in sampling density, which are common in 3D data.
Visual Data Association with No Feature Overlap
In some scenarios, such as when only cameras are used, 3D data will not be available or may be inaccurate and therefore only visual data can be used to associate detections amongst multiple views. One of the most challenging scenarios is when the camera positions have very large viewpoint differences, as will commonly be the case when the cameras are in geographically separate locations like in vehicles and street infrastructure. In these scenarios, traditional handcrafted visual features will not be sufficient to create correspondences due to the lack of common visual features and new methods must be developed.
We are examining different machine learning based approaches when applied to this scenario, which we have termed non-overlapping vehicle matching (NOVeM). In addition to developing algorithms for NOVeM, a dataset has been recorded to test and validate our proposed methods. The current dataset contains only two viewpoints; however, in the future we will use multiple cars equipped with stereo cameras and GPS sensors, as well as cameras deployed as street infrastructure, to record additional data with a higher number of concurrent sources. This will allow us to further examine both, vehicle-to-vehicle, and vehicle-to-street camera, vehicle matching for cases of both overlapping and non-overlapping visual features.

All Weather 3D Perception Using Cooperative Radars
Camera and LiDAR are light-based techniques and therefore cannot perceive the environment efficiently in extreme weather conditions. Light-based sensing modalities are easily affected by suspended dust or snow due to the extremely small wavelength of light (nanometers). Therefore, the perception capability of these sensors degrades in inclement weather conditions. In contrast to light-based sensing, wireless signals can penetrate through extreme weather conditions with relative ease and therefore provide the ability to perceive the environment in all-weather. We are enabling radar-based 3D geometry perception in extreme conditions, and fusing the radar data with camera data in order to eliminate the need for lidar -- this leads to cutting costs and increasing robustness at the same time.