Connected and Autonomous Vehicles
Vehicular and Edge Computing for Emerging Connected and Autonomous Vehicle Applications
Overview
Emerging connected and autonomous vehicles involve complex applications requiring not only optimal computing resource allocations but also efficient computing architectures. We investigate the critical performance metrics required for emerging vehicular computing applications and develop algorithms for optimal choices to satisfy the static and dynamic computing requirements in terms of the performance metrics. Employing the edge computing architectures for vehicular computing, we are developing different task partitioning and task offloading strategies.
Performance Metrics

Designing Optimal Computing Architecture for New Vehicles
Since future vehicles will have a widely varying set of capabilities and requirements, an important question comes up: what is the optimal computing architecture for a particular vehicle class. For example, given a number of camera sensors that need to be supported for a vehicle, and hence the number of machine vision (e.g., object detection and tracking) instances that need to be executed simultaneously, and the desired latency-power requirements of the instances, what may be the optimal computing architecture (number of CPU/GPU cores and their frequencies) that can satisfy the capability and the requirements.

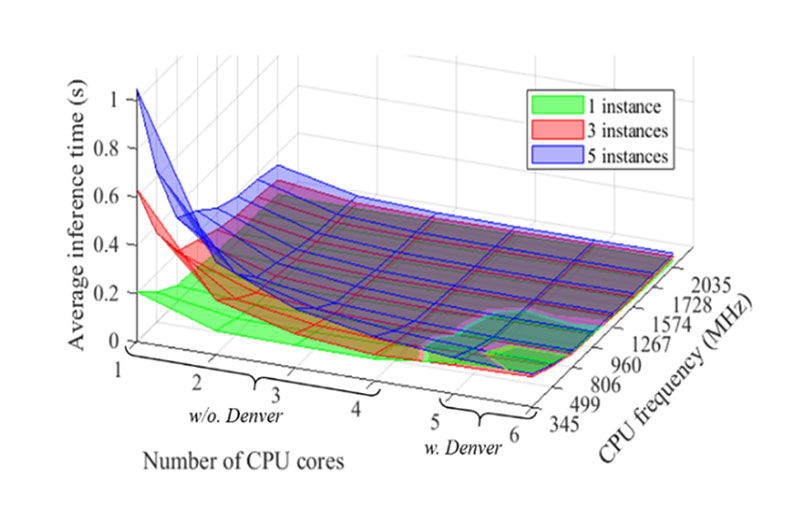
We explore the above question by conducting a preliminary experiment using an Nvidia Jetson Tx2 board to execute multiple SSD MobileNet v2 (object detection) instances, corresponding to the number of desired cameras for the vehicle, instances. The profiled relationship between the average inference time, capability, and the chosen architecture on Nvidia Jetson Tx2 board is shown below (left). In addition, the power consumption for running a variation of SSD MobileNet v2 instances on Nvidia Jetson Tx2 is shown by the right figure.
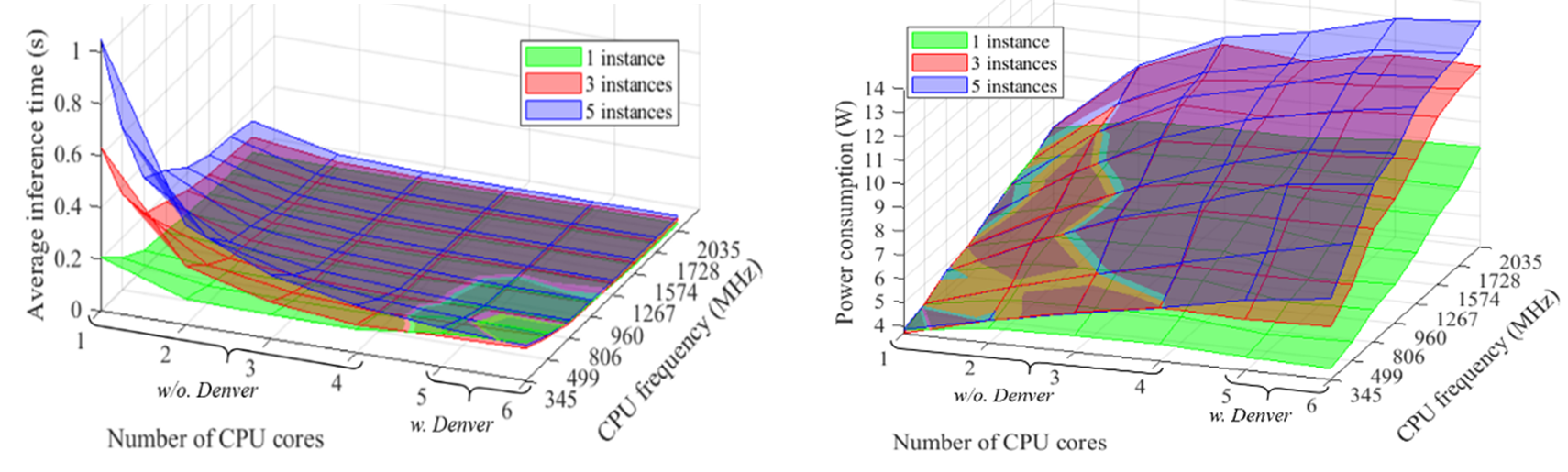
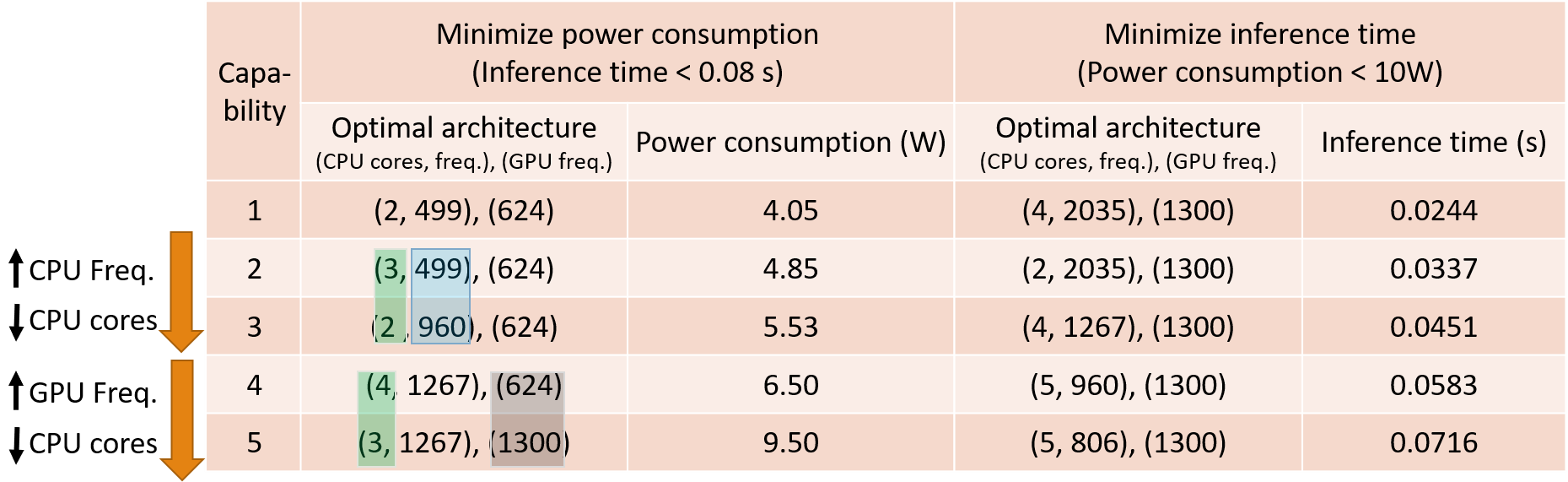
The data presented in the above figures show the possibility of developing models to estimate inference time and power consumption based on given requirements (instances) and architecture choices (number of cores, type of cores and frequency). Moreover, the models constructed can be used to help identify an optimal architecture for given capabilities and performance requirements of a set of vehicle applications. Below is an example of available architectures when the performance requirements are using 5 cameras and thereby 5 object detection instances, with maximum average inference time requirement of 0.08 s. Among all the architectures in Table II, if the objective is to minimize the power consumption, then the optimal architecture will be using 3 CPU cores at 1.267 GHz clock frequency, as the row highlighted shows.
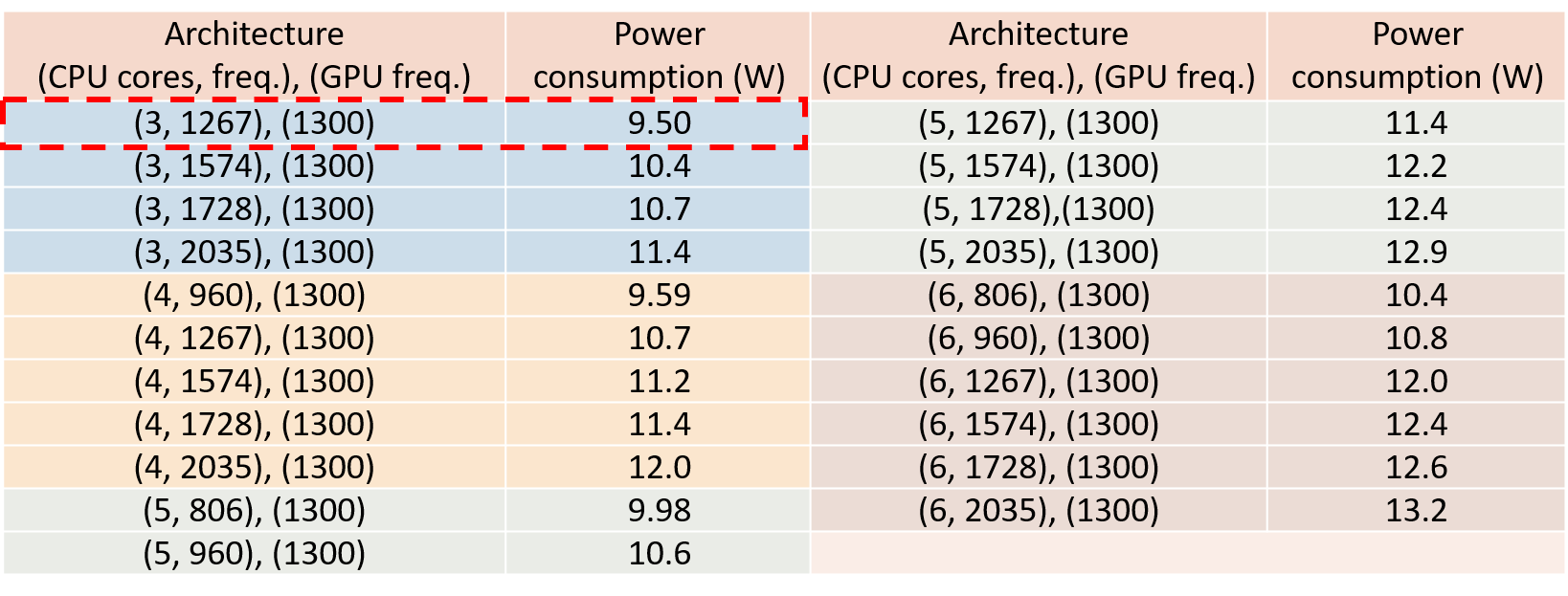
Following the same method, we can derive the following, which shows the optimal computing architecture, including various GPU clock frequency, for different capabilities to 1) minimize average inference time under the 10 W power consumption constraint, and 2) minimize power consumption while satisfying the 0.08s average inference time constraint. The optimal system architecture is shown in the format of: (Number of CPU cores, CPU clock frequency), (GPU clock frequency). The results show the tradeoff between changing the number of CPU cores as well as CPU and GPU clock frequencies to achieve the required objective.
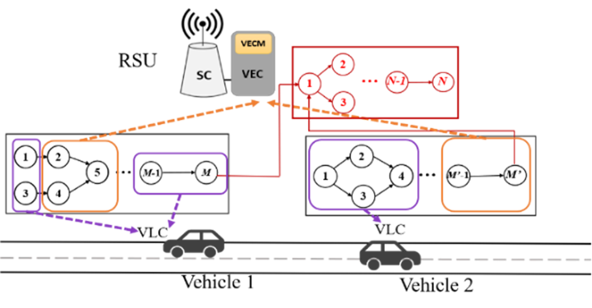
Collaborative Vehicular Edge Computing
Besides using Vehicular Local Computing (VLC), vehicular applications can leverage more powerful edge computing nodes, Vehicular Edge Computing (VEC), in intelligent Roadside Units (RSUs). Optimal Computation Offloading depends on dynamic availability of: 1. Computing capability of VLC and VEC, 2. Communication bandwidth, and 3. Task partitioning possible within the vehicular application. Therefore, Decision for partitioning and offloading tasks is nontrivial.
End-to-end Latency in Different Offloading Strategies
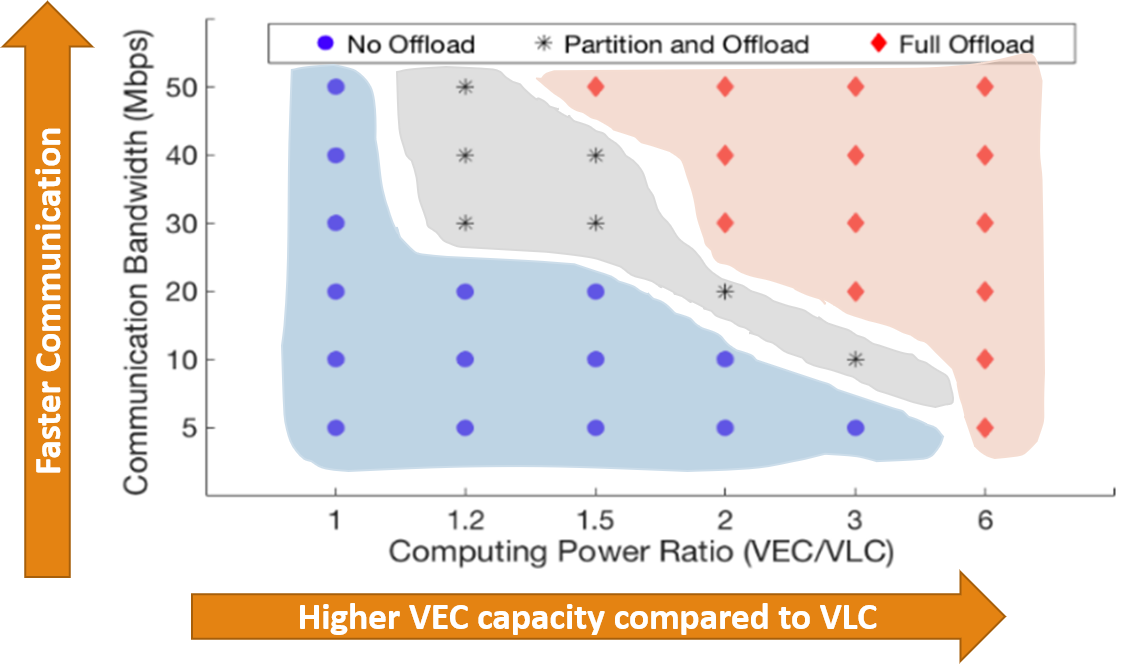
Different offloading policies are effective for minimizing end-to-end latency depending on available communication bandwidth.
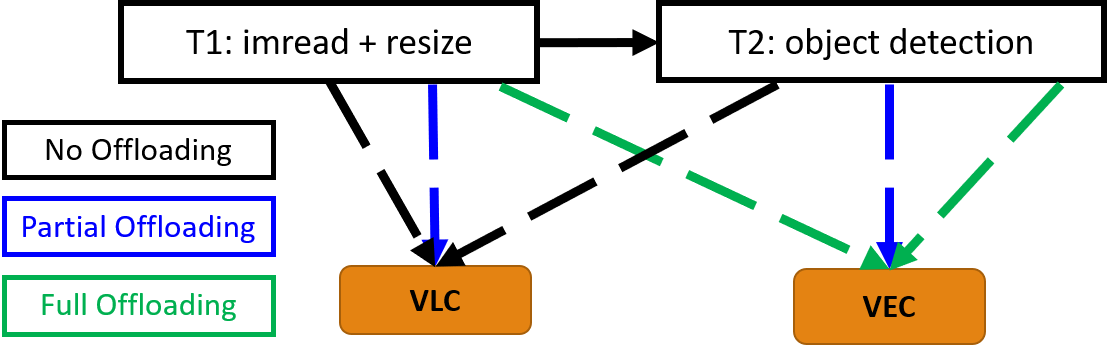
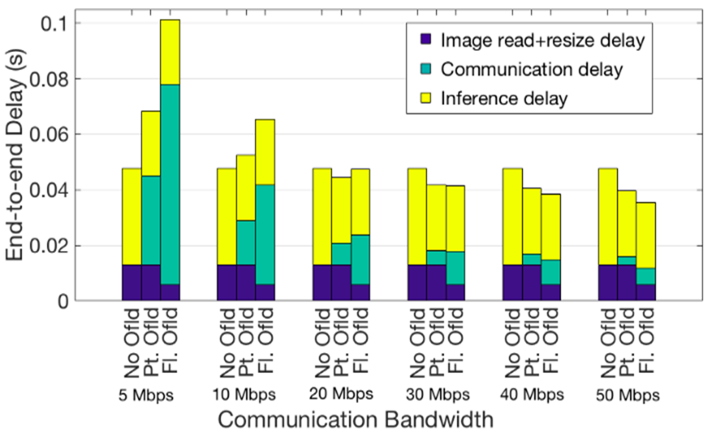
Firstly, when communication Bandwidth <= 10 Mbps, not offloading is the best choice. Secondly, when bandwidth is [20-30) Mbps, task partitioning and offloading can give the minimum latency. Finally, when the network quality improves further >= 30 Mbps, full offloading is the best choice. The figure below shows the optimal offloading decisions (in terms of minimum end-to-end delay) for varying VEC/VLC computing power ratio. It shows that when VLC unit is as powerful as VEC node, then irrespective of communication conditions, no offloading is the best policy. Similarly, when the VLC capability is six times inferior than the VEC, full offloading is the best policy even in weak network conditions e.g. 5 Mbps. For other computing power ratios, there are tradeoffs and the optimal choice can vary among three offloading policies.